msde: Bayesian Inference for Multivariate Stochastic Differential Equations
Source:R/msde-package.R
msde-package.RdImplements an MCMC sampler for the posterior distribution of arbitrary time-homogeneous multivariate stochastic differential equation (SDE) models with possibly latent components. The package provides a simple entry point to integrate user-defined models directly with the sampler's C++ code, and parallelizes large portions of the calculations when compiled with 'OpenMP'.
Details
See package vignettes; vignette("msde-quicktut") for a tutorial and vignette("msde-exmodels") for several example models.
Author
Maintainer: Martin Lysy mlysy@uwaterloo.ca
Authors:
Feiyu Zhu
JunYong Tong
Other contributors:
Trevor Kitt [contributor]
Nigel Delaney [contributor]
Examples
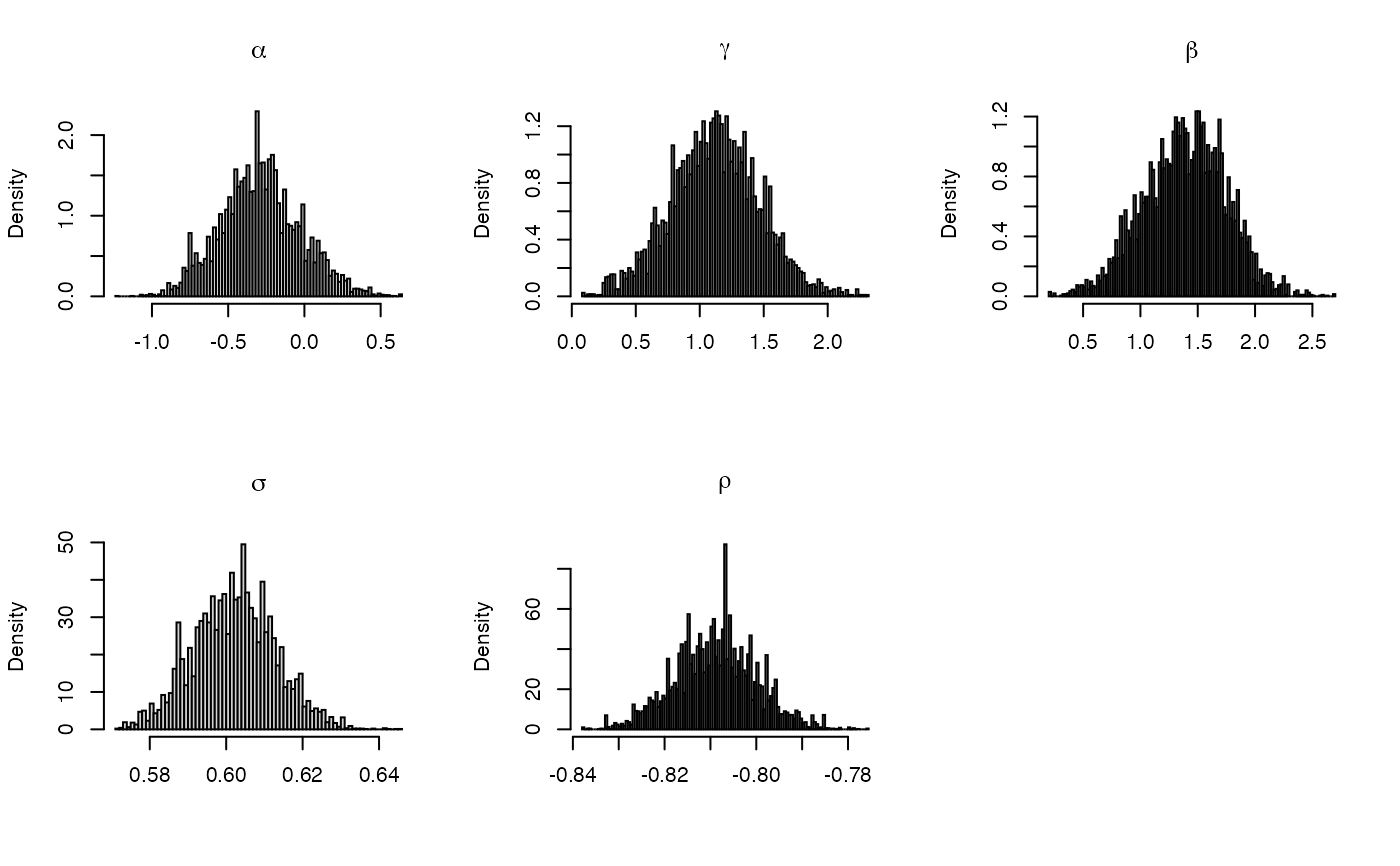
# \donttest{ # Posterior inference for Heston's model # compile model hfile <- sde.examples("hest", file.only = TRUE) param.names <- c("alpha", "gamma", "beta", "sigma", "rho") data.names <- c("X", "Z") hmod <- sde.make.model(ModelFile = hfile, param.names = param.names, data.names = data.names) # or simply load pre-compiled version hmod <- sde.examples("hest") # Simulate data X0 <- c(X = log(1000), Z = 0.1) theta <- c(alpha = 0.1, gamma = 1, beta = 0.8, sigma = 0.6, rho = -0.8) dT <- 1/252 nobs <- 1000 hest.sim <- sde.sim(model = hmod, x0 = X0, theta = theta, dt = dT, dt.sim = dT/10, nobs = nobs)#>#>#>#># initialize MCMC sampler # both components observed, no missing data between observations init <- sde.init(model = hmod, x = hest.sim$data, dt = hest.sim$dt, theta = theta) # Initialize posterior sampling argument nsamples <- 1e4 burn <- 1e3 hyper <- NULL # flat prior hest.post <- sde.post(model = hmod, init = init, hyper = hyper, nsamples = nsamples, burn = burn)#>#>#>#>#>#>#>#>#># plot the histogram for the sampled parameters par(mfrow = c(2,3)) for(ii in 1:length(hmod$param.names)) { hist(hest.post$params[,ii],breaks=100, freq = FALSE, main = parse(text = hmod$param.names[ii]), xlab = "") } # }