Inference for Multivariate Stochastic Differential Equations with msde
Martin Lysy, JunYong Tong, Nigel Delaney
2021-12-17
Source:vignettes/msde-quicktut.Rmd
msde-quicktut.RmdIntroduction
A \(d\)-dimensional stochastic differential equation (SDE) \(\boldsymbol{Y}_t = (Y_{1t}, \ldots, Y_{dt})\) is written as \[ \mathrm{d}\boldsymbol{Y}_t = \boldsymbol{\Lambda}_{\boldsymbol{\theta}}(\boldsymbol{Y}_t)\,\mathrm{d}t + \boldsymbol{\Sigma}_{\boldsymbol{\theta}}(\boldsymbol{Y}_t)^{1/2}\,\mathrm{d}\boldsymbol{B}_t, \] where \(\boldsymbol{\Lambda}_{\boldsymbol{\theta}}(\boldsymbol{y})\) and \(\boldsymbol{\Sigma}_{\boldsymbol{\theta}}(\boldsymbol{y})\) are the drift and diffusion functions, and \(\boldsymbol{B}_t = (B_{1t}, \ldots, B_{dt})\) is \(d\)-dimensional Brownian motion. The msde package implements a Markov Chain Monte Carlo (MCMC) algorithm to sample from the posterior distribution \(p(\boldsymbol{\theta}\mid \boldsymbol{Y})\) of the parameters given discrete observations \(\boldsymbol{Y}= (\boldsymbol{Y}_0, \ldots, \boldsymbol{Y}_N)\) recorded at times \(t_0, \ldots, t_N\), with some of the \(d\) components of \(\boldsymbol{Y}_t\) possibly latent. To do this efficiently, msde requires on-the-fly C++ compiling of user-specified models. Instructions for setting up R to compile C++ code are provided in the Installation section.
Creating an sde.model object
The SDE model used throughout this vignette is the so-called Lotka-Volterra predator-prey model. Let \(H_t\) and \(L_t\) denote the number of Hare and Lynx at time \(t\) coexisting in a given habitat. The Lotka-Volterra SDE describing the interactions between these two animal populations is given by (Golightly and Wilkinson 2010): \[ \begin{bmatrix} \mathrm{d} H_t \\ \mathrm{d} L_t \end{bmatrix} = \begin{bmatrix} \alpha H_t - \beta H_tL_t \\ \beta H_tL_t - \gamma L_t \end{bmatrix}\, \mathrm{d} t + \begin{bmatrix} \alpha H_t + \beta H_tL_t & -\beta H_tL_t \\ -\beta H_tL_t & \beta H_tL_t + \gamma L_t\end{bmatrix}^{1/2} \begin{bmatrix} \mathrm{d} B_{1t} \\ \mathrm{d} B_{2t} \end{bmatrix}. \] Thus we have \(d = 2\), \(\boldsymbol{Y}_t = (H_t, L_t)\), and \(\boldsymbol{\theta}= (\alpha, \beta, \gamma)\).
The sdeModel class definition
In order to build this model in C++, we create a header file lotvolModel.h containing the class definition for an sdeModel object. The basic structure of this class is given below:
// sde model object
class sdeModel {
public:
static const int nParams = 3; // number of model parameters
static const int nDims = 2; // number of sde dimensions
static const bool sdDiff = false; // whether diffusion function is on sd or var scale
static const bool diagDiff = false; // whether diffusion function is diagonal
void sdeDr(double *dr, double *x, double *theta); // drift function
void sdeDf(double *df, double *x, double *theta); // diffusion function
bool isValidParams(double *theta); // parameter validator
bool isValidData(double *x, double *theta); // data validator
};The meaning of each class member is as follows:
nParams: The number of model parameters. For the Lotka-Volterra model we have \(\boldsymbol{\theta}= (\alpha, \beta, \gamma)\), such thatnParams = 3.nDims: The number of dimensions in the multivariate SDE. In this case we have \(\boldsymbol{Y}_t = (H_t, L_t)\), such thatnDims = 2.-
sdeDr: The SDE drift function. In R, this function would be implemented assde.drift <- function(x, theta) { dr <- c(theta[1]*x[1] - theta[2]*x[1]*x[2], # alpha * H - beta * H*L theta[2]*x[1]*x[2] - theta[3]*x[2]) # beta * H*L - gamma * L dr }In C++ the same thing is accomplished with
-
sdeDf: The SDE diffusion function. This can be specified on the standard deviation scale, or on the variance scale as above. In this case, an R implementation would besde.diff <- function(x, theta) { df <- matrix(NA, 2, 2) df[1,1] <- theta[1]*x[1] + theta[2]*x[1]*x[2] # alpha * H + beta * H*L df[1,2] <- -theta[2]*x[1]*x[2] # -beta * H*L df[2,1] <- df[1,2] # -beta * H*L df[2,2] <- theta[2]*x[1]*x[2] + theta[3]*x[2] # beta * H*L + gamma * L df }In C++ the specification is slightly different. First we set
sdDiff = falsein order to tell msde to use the variance scale. Next, the diffusion function is coded asvoid sdeDf(double *df, double *x, double *theta) { df[0] = theta[0]*x[0] + theta[1]*x[0]*x[1]; // matrix element (1,1) df[2] = -theta[1]*x[0]*x[1]; // element (1,2) df[3] = theta[1]*x[0]*x[1] + theta[2]*x[1]; // element (2,2) return; }Thus there are two major differences with the R version. The first is that the
dfmatrix is stored as a vector (or “array” in C++). Its elements are stored in column-major order, i.e., by stacking the columns one after the other into one long vector. The second difference is that msde only uses the upper triangular portion of the (symmetric) matrix \(\boldsymbol{\Sigma}_{\boldsymbol{\theta}}(\boldsymbol{y})\). The elements below the diagonal can be set to any value or not set at all without affecting the computations.msde internally computes the Cholesky decomposition of the diffusion function when it is specified on the variance scale. For small problems such as this one, it is more efficient to specify the Cholesky decomposition directly, i.e., specify the diffusion on the standard deviation scale. In this case, the Cholesky decomposition of the diffusion function is
\[ \begin{bmatrix} \alpha H_t + \beta H_tL_t & -\beta H_tL_t \\ -\beta H_tL_t & \beta H_tL_t + \gamma L_t\end{bmatrix}^{1/2} = \begin{bmatrix} \sqrt{\alpha H_t + \beta H_tL_t} & -\frac{\beta H_tL_t}{\sqrt{\alpha H_t + \beta H_tL_t}} \\ 0 & \sqrt{\beta H_tL_t + \gamma L_t - \frac{(\beta H_tL_t)^2}{\alpha H_t + \beta H_tL_t}} \end{bmatrix}, \]
which is passed to msde by setting
sdDiff = trueand -
diagDiff: A logical specifying whether or not the diffusion matrix \(\boldsymbol{\Sigma}_\boldsymbol{\theta}(\boldsymbol{y})\) is diagonal. For the Lotka-Volterra SDE model above, we setdiagDiff = false. However, if the diffusion function were of the form\[ \boldsymbol{\Sigma}_\boldsymbol{\theta}(\boldsymbol{Y}_t) = \begin{bmatrix} \alpha H_t + \beta H_tL_t & 0 \\ 0 & \beta H_tL_t + \gamma L_t\end{bmatrix}, \]
then we would set
diagDiff = true, and importantly, treat thedfargument ofsdeDfdirectly as the diagonal elements of the diffusion matrix. That is, the diffusion (on the variance scale) is encoded asvoid sdeDf(double *df, double *x, double *theta) { double bHL = theta[1]*x[0]*x[1]; // beta * H*L df[0] = theta[0]*x[0] + bHL; // alpha * H + bHL // note the assignment to df[1] and not df[3] df[1] = bHL + theta[2]*x[1]; // bHL + gamma * L return; }NOTE: The msde C++ library does not initialize output pointers
dfanddr. So, if these contain zeros they must be assigned explicitly. -
isValidParams: A logical used to specify the parameter support. In this case we have \(\alpha, \beta, \gamma> 0\), such that -
isValidData: A logical used to specify the SDE support, which can be parameter-dependent. In this case we simply have \(H_t, L_t > 0\), such that
Thus the whole file lotvolModel.h is given below:
#ifndef sdeModel_h
#define sdeModel_h 1
// Lotka-Volterra Predator-Prey model
// class definition
class sdeModel {
public:
static const int nParams = 3; // number of model parameters
static const int nDims = 2; // number of sde dimensions
static const bool diagDiff = false; // whether diffusion function is diagonal
static const bool sdDiff = true; // whether diffusion is on sd or var scale
void sdeDr(double *dr, double *x, double *theta); // drift function
void sdeDf(double *df, double *x, double *theta); // diffusion function
bool isValidParams(double *theta); // parameter validator
bool isValidData(double *x, double *theta); // data validator
};
// drift function
inline void sdeModel::sdeDr(double *dr, double *x, double *theta) {
dr[0] = theta[0]*x[0] - theta[1]*x[0]*x[1]; // alpha * H - beta * H*L
dr[1] = theta[1]*x[0]*x[1] - theta[2]*x[1]; // beta * H*L - gamma * L
return;
}
// diffusion function (sd scale)
inline void sdeModel::sdeDf(double *df, double *x, double *theta) {
double bHL = theta[1]*x[0]*x[1]; // beta * H*L
df[0] = sqrt(theta[0]*x[0] + bHL); // sqrt(alpha * H + bHL)
df[2] = -bHL/df[0];
df[3] = sqrt(bHL + theta[2]*x[1] - df[2]*df[2]);
return;
}
// parameter validator
inline bool sdeModel::isValidParams(double *theta) {
bool val = theta[0] > 0.0;
val = val && theta[1] > 0.0;
val = val && theta[2] > 0.0;
return val;
}
// data validator
inline bool sdeModel::isValidData(double *x, double *theta) {
return (x[0] > 0.0) && (x[1] > 0.0);
}
#endifThe additions to the previous code sections are:
- The header include guards (
#ifndef/#define/#endif). - The
sdeModel::identifier is prepended to the class member definitions when these are written outside of the class declaration itself. - The
inlinekeyword before the class member definitions, both of which ensure that only one instance of these functions is passed to the C++ compiler.
Compiling and checking the sde.model object
One the sdeModel class is created as the C++ level, it is compiled in R using the following commands:
## Loading required package: msde
# put lotvolModel.h in the working directory
data.names <- c("H", "L")
param.names <- c("alpha", "beta", "gamma")
lvmod <- sde.make.model(ModelFile = "lotvolModel.h",
data.names = data.names,
param.names = param.names)Before using the model for inference, it is useful to make sure that the C++ entrypoints are error-free. To facilitate this, msde provides R wrappers to the internal C++ drift, diffusion, and validator functions, which can then be checked against R versions as follows:
# helper functions
# random matrix of size nreps x length(x) from vector x
jit.vec <- function(x, nreps) {
apply(t(replicate(n = nreps, expr = x, simplify = "matrix")), 2, jitter)
}
# maximum absolute and relative error between two arrays
max.diff <- function(x1, x2) {
c(abs = max(abs(x1-x2)), rel = max(abs(x1-x2)/max(abs(x1), 1e-8)))
}
# R sde functions
# drift and diffusion
lv.drift <- function(x, theta) {
dr <- c(theta[1]*x[1] - theta[2]*x[1]*x[2], # alpha * H - beta * H*L
theta[2]*x[1]*x[2] - theta[3]*x[2]) # beta * H*L - gamma * L
dr
}
lv.diff <- function(x, theta) {
df <- matrix(NA, 2, 2)
df[1,1] <- theta[1]*x[1] + theta[2]*x[1]*x[2] # alpha * H + beta * H*L
df[1,2] <- -theta[2]*x[1]*x[2] # -beta * H*L
df[2,1] <- df[1,2] # -beta * H*L
df[2,2] <- theta[2]*x[1]*x[2] + theta[3]*x[2] # beta * H*L + gamma * L
chol(df) # always use sd scale in R
}
# validators
lv.valid.data <- function(x, theta) all(x > 0)
lv.valid.params <- function(theta) all(theta > 0)
# generate some test values
nreps <- 12
x0 <- c(H = 71, L = 79)
theta0 <- c(alpha = .5, beta = .0025, gamma = .3)
X <- jit.vec(x0, nreps)
Theta <- jit.vec(theta0, nreps)
# drift and diffusion check
# R versions
dr.R <- matrix(NA, nreps, lvmod$ndims) # drift
df.R <- matrix(NA, nreps, lvmod$ndims^2) # diffusion
for(ii in 1:nreps) {
dr.R[ii,] <- lv.drift(x = X[ii,], theta = Theta[ii,])
# flattens diffusion matrix into a row
df.R[ii,] <- c(lv.diff(x = X[ii,], theta = Theta[ii,]))
}
# C++ versions
dr.cpp <- sde.drift(model = lvmod, x = X, theta = Theta)
df.cpp <- sde.diff(model = lvmod, x = X, theta = Theta)
# compare
max.diff(dr.R, dr.cpp)## abs rel
## 3.552714e-15 1.571480e-16
max.diff(df.R, df.cpp)## abs rel
## 8.881784e-16 1.243854e-16
# validator check
# generate invalid data and parameters
X.bad <- X
X.bad[c(1,3,5),1] <- -X.bad[c(1,3,5),1]
Theta.bad <- Theta
Theta.bad[c(2,4,6),3] <- -Theta.bad[c(2,4,6),3]
# R versions
x.R <- rep(NA, nreps)
theta.R <- rep(NA, nreps)
for(ii in 1:nreps) {
x.R[ii] <- lv.valid.data(x = X.bad[ii,], theta = Theta.bad[ii,])
theta.R[ii] <- lv.valid.params(theta = Theta.bad[ii,])
}
# C++ versions
x.cpp <- sde.valid.data(model = lvmod, x = X.bad, theta = Theta.bad)
theta.cpp <- sde.valid.params(model = lvmod, theta = Theta.bad)
# compare
c(x = all(x.R == x.cpp), theta = all(theta.R == theta.cpp))## x theta
## TRUE TRUESimulating trajectories from the Lotka-Volterra model
The basis for both simulation and inference with SDEs is the Euler-Maruyama approximation (Maruyama 1955), which states that over a small time interval \(\Delta t\), the (intractable) transition density of the SDE can be approximated by
\[ \boldsymbol{Y}_{t+\Delta t} \mid \boldsymbol{Y}_t \approx \mathcal{N}\Big(\boldsymbol{Y}_t + \boldsymbol{\Lambda}_\boldsymbol{\theta}(\boldsymbol{Y}_t)\Delta t, \boldsymbol{\Sigma}_\boldsymbol{\theta}(\boldsymbol{Y}_t)\Delta t\Big), \]
with convergence to the true SDE dynamics as \(\Delta t\to 0\).
In order to simulate data from the Lotka-Volterra SDE model, we use the function sde.sim(). Here we’ll generate \(N = 50\) observations of the process with initial values \(\boldsymbol{Y}_0 = (71, 79)\), and parameter values \(\boldsymbol{\theta}= (.5, .0025,.3)\), with time between observations of \(\Delta t= 1\) year. The dt.sim argument to sde.sim() specifies the internal observation time used by the Euler-Maruyama approximation.
# simulation parameters
theta0 <- c(alpha = .5, beta = .0025, gamma = .3) # true parameter values
x0 <- c(H = 71, L = 79) # initial SDE values
N <- 50 # number of observations
dT <- 1 # time between observations (years)
# simulate data
lvsim <- sde.sim(model = lvmod, x0 = x0, theta = theta0,
nobs = N-1, # N-1 steps forward
dt = dT,
dt.sim = dT/100) # internal observation time## Number of normal draws required: 4900## Running simulation...## Execution time: 0 seconds.## Bad Draws = 0
# plot data
Xobs <- rbind(c(x0), lvsim$data) # include first observation
tseq <- (1:N-1)*dT # observation times
clrs <- c("black", "red")
par(mar = c(4, 4, 1, 0)+.1)
plot(x = 0, type = "n", xlim = range(tseq), ylim = range(Xobs),
xlab = "Time (years)", ylab = "Population")
lines(tseq, Xobs[,"H"], type = "o", pch = 16, col = clrs[1])
lines(tseq, Xobs[,"L"], type = "o", pch = 16, col = clrs[2])
legend("topleft", legend = c("Hare", "Lynx"), fill = clrs)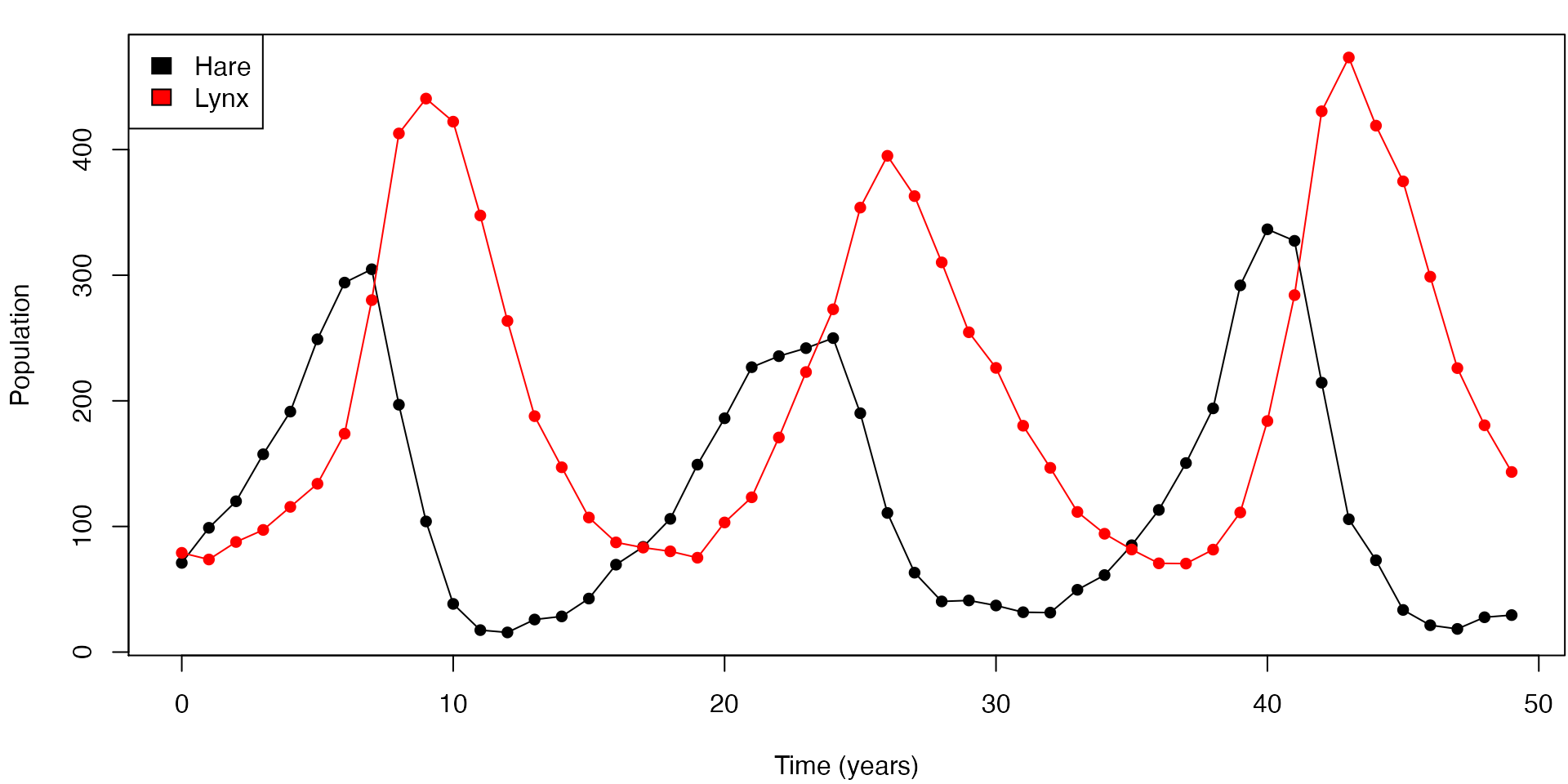
Inference for multivariate SDE models
Parameter inference is conducted used a well-known data augmentation scheme due to Pedersen (1995). Assume that, as above, the SDE observations are evenly spaced with interobservation time \(\Delta t\). For any integer \(m > 0\), let \(\boldsymbol{Y}_{(m)} = (\boldsymbol{Y}_{m,0}, \ldots, \boldsymbol{Y}_{m,Nm})\) denote the value of the SDE at equally spaced intervals of \(\Delta t_m = \Delta t/m\). Thus, \(\boldsymbol{Y}_{(1)} = \boldsymbol{Y}\) corresponds to the observed data, and for \(m > 1\), we have \(\boldsymbol{Y}_{m,nm} = \boldsymbol{Y}_n\). Thus we shall refer to the “missing data” as \(\boldsymbol{Y}_{\mathrm{miss}}= \boldsymbol{Y}_{(m)} \setminus \boldsymbol{Y}\). The Euler-Maruyama approximation to the complete likelihood is
\[ \mathcal L(\boldsymbol{\theta}\mid \boldsymbol{Y}_{(m)}) = \prod_{n=0}^{Nm-1} \varphi\Big(\boldsymbol{Y}_{m,n+1} \mid \boldsymbol{Y}_{m,n} + \boldsymbol{\Lambda}_\boldsymbol{\theta}(\boldsymbol{Y}_{m,n})\Delta t_m, \boldsymbol{\Sigma}_\boldsymbol{\theta}(\boldsymbol{Y}_{m,n}\Delta t)\Big), \]
where \(\varphi(\boldsymbol{y}\mid \mathbf \mu, \mathbf \Sigma)\) is the PDF of \(\boldsymbol{y}\sim \mathcal{N}(\mathbf \mu, \mathbf \Sigma)\). The Bayesian data augmentation scheme then consists of chosing a prior \(\pi(\boldsymbol{\theta})\) and sampling from the posterior distribution
\[ p_m(\boldsymbol{\theta}\mid \boldsymbol{Y}) = \int \mathcal L(\boldsymbol{\theta}\mid \boldsymbol{Y}_{(m)}) \times \pi(\boldsymbol{\theta}) \, \mathrm{d}\boldsymbol{Y}_{\mathrm{miss}}. \]
As \(m \to \infty\) this approximate posterior converges to the true SDE posterior \(p(\boldsymbol{\theta}\mid \boldsymbol{Y})\).
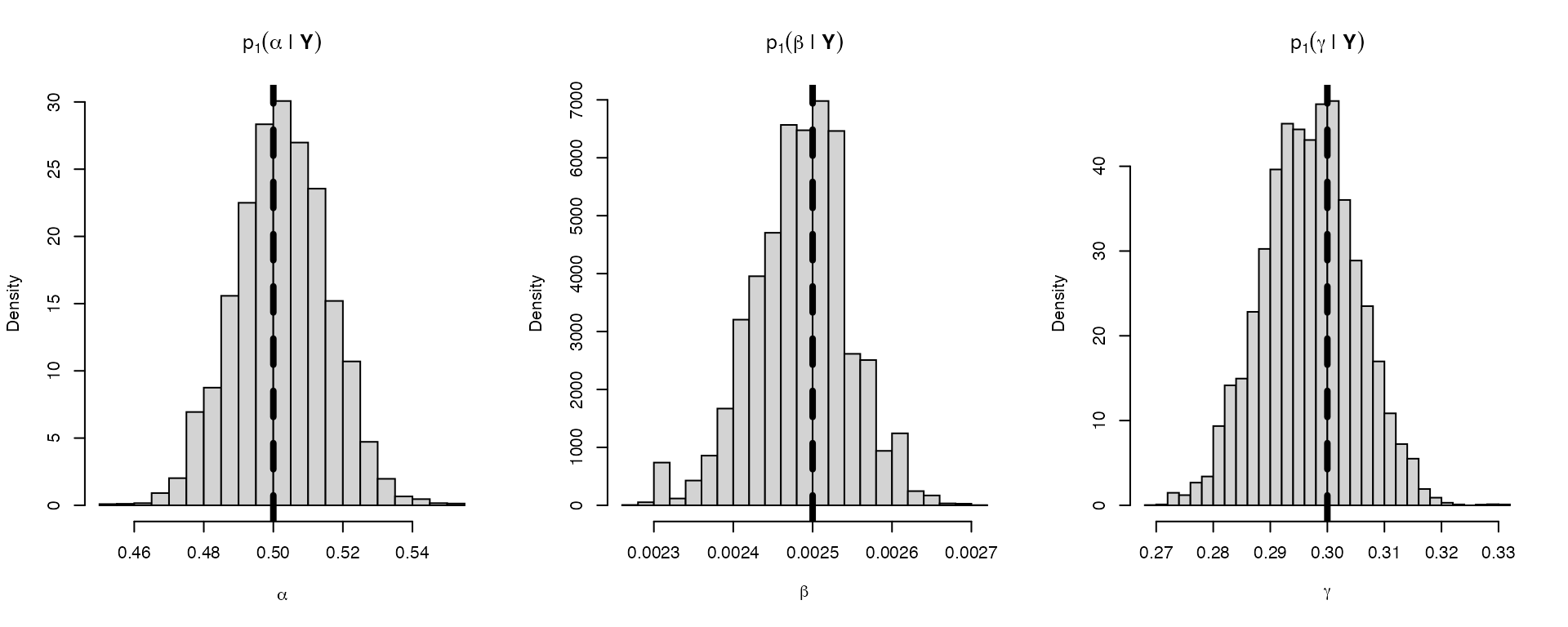
Posterior sampling from the Euler-Maruyama posterior is accomplished with the function sde.post(). In the following example we use \(m = 1\), i.e., there is no missing data. We’ll use a Lebesgue prior \(\pi(\boldsymbol{\theta}) \propto 1\); more information on the default and custom prior specifications can be found in the following sections.
# initialize the posterior sampler
init <- sde.init(model = lvmod, x = Xobs, dt = dT,
m = 1, theta = c(.1, .1, .1))
nsamples <- 2e4
burn <- 2e3
lvpost <- sde.post(model = lvmod, init = init,
hyper = NULL, #prior specification
nsamples = nsamples, burn = burn)## Output size:## params = 60000## Running posterior sampler...## Execution time: 0.16 seconds.## alpha accept: 43.9%## beta accept: 42.7%## gamma accept: 44.6%
# posterior histograms
tnames <- expression(alpha, beta, gamma)
par(mfrow = c(1,3))
for(ii in 1:lvmod$nparams) {
hist(lvpost$params[,ii], breaks = 25, freq = FALSE,
xlab = tnames[ii],
main = parse(text = paste0("p[1](", tnames[ii], "*\" | \"*bold(Y))")))
# superimpose true parameter value
abline(v = theta0[ii], lwd = 4, lty = 2)
}
Missing data specification with sde.init()
In the example above there was no missing data, i.e., \(m = 1\) and both components of the SDE are observed at each time \(t_0, \ldots, t_N\). In order to refine the Euler-Maruyama approximation, we simply pass a larger value of \(m\) to sde.init():
# 3 missing data points between each observation, so dt_m = dt/4
m <- 4
init <- sde.init(model = lvmod, x = Xobs, dt = dT,
m = m, theta = c(.1, .1, .1))We can also assume that only the first \(q < d\) components of the SDE are observed, with the last \(d-q\) being latent. In this case with \(q = 1\), the lynx population would be unobserved, and this is specified with the nvar.obs argument:
init <- sde.init(model = lvmod, x = Xobs, dt = dT,
nvar.obs = 1, # number of "observed" variables per timepoint
m = m, theta = c(.1, .1, .1))Note that the initial data x must still be supplied as an \((N+1) \times d\) matrix, with the missing values corresponding to initial values for the MCMC sampler.
Default prior specification
Since msde allows for some of the \(q\) components of \(\boldsymbol{Y}_t\) to be latent, a prior must be specified not only for \(\boldsymbol{\theta}\) but also for the latent variables in the initial observation \(\boldsymbol{Y}_0\).
In the example above, we assumed a Lebesgue prior \(\pi(\boldsymbol{\theta}, \boldsymbol{Y}_0) \propto 1\), with the restriction that \(\boldsymbol{\theta}, \boldsymbol{Y}_0 > 0\) (as specified in the sdeModel class definition via the isValidData and isValidParams validators).
Default prior
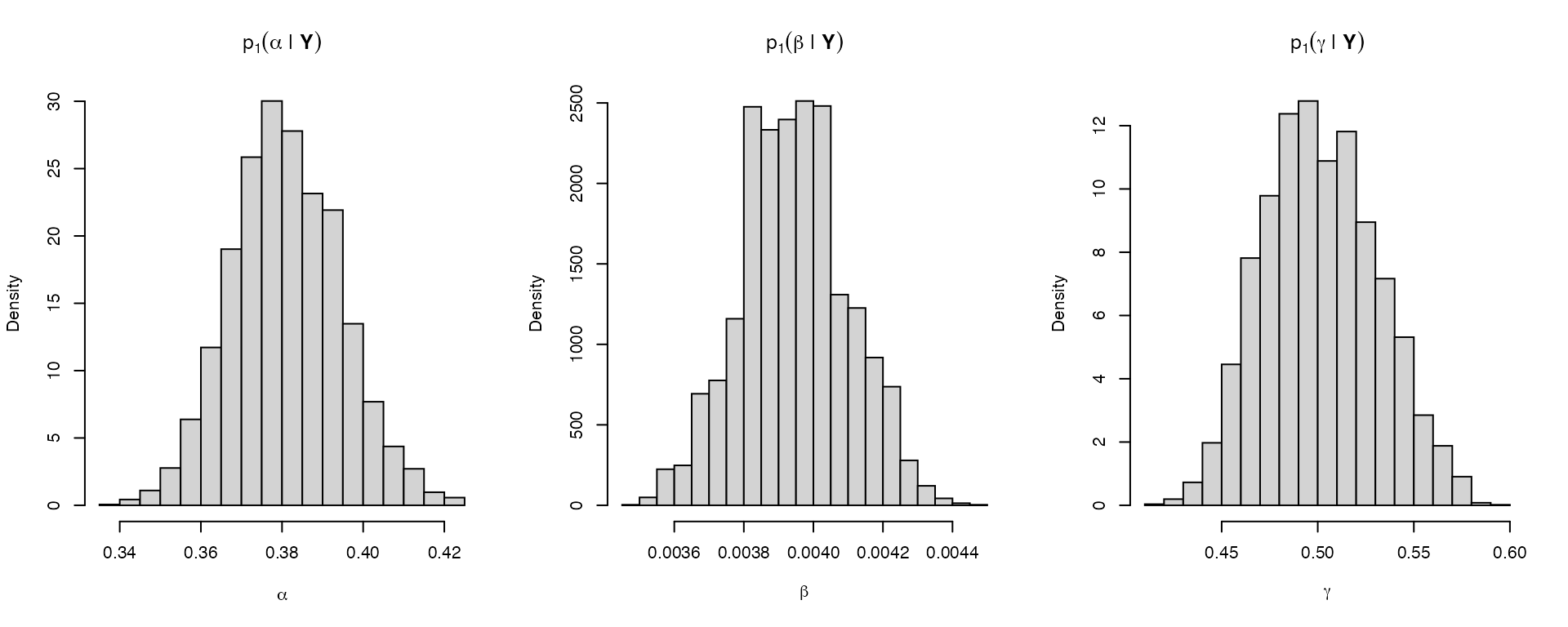
The default prior in msde is a multivariate normal, for which the (fixed) hyper-parameters are supplied via the hyper argument to sde.post(). The hyper argument can either be NULL, or a list with elements mu and Sigma. These consist of a named vector named matrix specifying the mean and variance of the named elements. Unnamed elements are given a Lebesgue prior. So for example, posterior inference for the dataset above with \(m = 1\), latent variable \(L\), and prior distribution
\[ L_0, \alpha, \gamma \stackrel{\mathrm{iid}}{\sim}\mathcal{N}(1, 1), \qquad \pi(H_0, \beta \mid H_0, \alpha, \gamma) \propto 1 \]
is obtained as follows:
# prior specification
pnames <- c("L", "alpha", "gamma")
hyper <- list(mu = rep(1, 3), Sigma = diag(3))
names(hyper$mu) <- pnames
dimnames(hyper$Sigma) <- list(pnames, pnames)
# initialize the posterior sampler
init <- sde.init(model = lvmod, x = Xobs, dt = dT,
m = 1, nvar.obs = 1, # L is latent
theta = c(.1, .1, .1))
nsamples <- 2e4
burn <- 2e3
lvpost <- sde.post(model = lvmod, init = init,
hyper = hyper, #prior specification
nsamples = nsamples, burn = burn)## Output size:## params = 60000## data = 2e+05## Running posterior sampler...## Execution time: 0.45 seconds.## Bridge accept: min = 1.31%, avg = 42%## alpha accept: 43.8%## beta accept: 43.6%## gamma accept: 43.9%## L0 accept: 98.7%
# posterior histograms
tnames <- expression(alpha, beta, gamma)
par(mfrow = c(1,3))
for(ii in 1:lvmod$nparams) {
hist(lvpost$params[,ii], breaks = 25, freq = FALSE,
xlab = tnames[ii],
main = parse(text = paste0("p[1](", tnames[ii], "*\" | \"*bold(Y))")))
# superimpose true parameter value
abline(v = theta0[ii], lwd = 4, lty = 2)
}
Custom prior specification
msde provides a two-stage mechanism for specifying user-defined priors. This is illustrated below with a simple log-normal prior on \(\boldsymbol{\eta}= (\alpha, \gamma, \beta, L_0) = (4_{\eta },\ldots,4_{)}\), namely
\[ \pi(\boldsymbol{\eta}) \iff \log(\eta_i) \stackrel{\mathrm{iid}}{\sim}\mathcal{N}(\mu_i, \sigma_i^2), \]
where the hyperparameters are \(\boldsymbol{\mu }= (4_{\mu },\ldots,4_{)}\) and \(\boldsymbol{\sigma }= (4_{\sigma },\ldots,4_{)}\). Ultimately, the hyperparameters will be passed to sde.post() as a two-element list, e.g.,
The sdePrior class definition
The first step of the prior specification is to define it at the C++ level, through the sdPrior class. The class corresponding to the log-normal prior above is defined in the file lotvolPrior.h pasted below.
#ifndef sdePrior_h
#define sdePrior_h 1
#include <Rcpp.h> // contains R's dlnorm function
// Prior for Lotka-Volterra Model
class sdePrior {
private:
static const int nHyper = 4; // (alpha, beta, gamma, L)
double *mean, *sd; // log-normal mean and standard deviation vectors
public:
double logPrior(double *theta, double *x); // log-prior function
sdePrior(double **phi, int nArgs, int *nEachArg); // constructor
~sdePrior(); // destructor
};
// constructor
inline sdePrior::sdePrior(double **phi, int nArgs, int *nEachArg) {
// allocate memory for hyperparameters
mean = new double[nHyper];
sd = new double[nHyper];
// hard-copy hyperparameters into Prior object
for(int ii=0; ii<nHyper; ii++) {
mean[ii] = phi[0][ii];
sd[ii] = phi[1][ii];
}
}
// destructor
inline sdePrior::~sdePrior() {
// deallocate memory to avoid memory leaks
delete [] mean;
delete [] sd;
}
// log-prior function itself:
// independent log-normal densities for (alpha,beta,gamma,L)
inline double sdePrior::logPrior(double *theta, double *x) {
double lpi = 0.0;
// alpha,beta,gamma
for(int ii=0; ii < 3; ii++) {
lpi += R::dlnorm(theta[ii], mean[ii], sd[ii], 1);
}
// L
lpi += R::dlnorm(x[1], mean[3], sd[3], 1);
return lpi;
}
#endifThe meaning of each class member is as follows:
-
sdePrior: The class constructor. This is how the C++ code collects the hyperparameters from R. Its argument signature must be matched exactly and has the following meaning:-
phi: A double-pointers of typedouble. This is a simple mechanism to give the address of the elements of a list of numeric vectors, as the hyperparameters are defined on the R side. So with the example above, \(\sigma_2\) is pointed to byphi[1][1]. -
nArgs: The number of elements in the hyperparameter vector, i.e.,length(hyper), which in this case is 2. In this case this number is known in advance, but for greater flexibility it is determined at runtime automatically in the C++ code from the specific value ofhyper. -
nEachArg: The length of each hyperparameter element, i.e.,sapply(hyper, length). Again this is determined automatically from the C++ code. Note that for speed considerations, the contents ofphishould be copied directly into thesdePriorobject, held here in the private membersmeanandsd.
-
-
~sdePrior: The class destructor, which is needed to deallocate the dynamic memory to prevent memory leaks. -
logPrior: The log-prior function itself, of which the signature must be matched exactly. Its arguments correspond to \(\boldsymbol{\theta}\) and \(\boldsymbol{Y}_0\). In this case, we use the C++ version of R’sdlnormfunction, which is accessible by includingRcpp.h.
Formatting the R input to the C++ code
C++ is much less forgiving that R when it comes to accepting incorrect inputs. Thus, if a user accidently passed the hyperparameters to sde.post() as e.g.,
at best this would cause garbage MCMC output and at worst, the R session to terminate abruptly. For this reason msde provides an input-checking mechanism, which can also used to format the hyperparameters into the list-of-numeric-vectors input expected by the C++ code. This is done by passing an appropriate input checking function to sde.make.model() through the argument hyper.check. This argument accepts a function with the exact signature of the example below. In this example, hyper must be a list with elements mu and sigma, which are either:
- Scalars, in which case each is replicated four times.
- Vectors of length four, in which case the order is determined by \(\boldsymbol{\eta}= (\alpha, \beta, \gamma, L_0)\).
# must match argument signature _exactly_
lvcheck <- function(hyper, param.names, data.names) {
if(is.null(names(hyper)) ||
!identical(sort(names(hyper)), c("mu", "sigma"))) {
stop("hyper must be a list with elements mu and sigma.")
}
mu <- hyper$mu
if(length(mu) == 1) mu <- rep(mu, 4)
if(!is.numeric(mu) || length(mu) != 4) {
stop("mu must be a numeric scalar or vector of length four.")
}
sig <- hyper$sigma
if(length(sig) == 1) sig <- rep(sig, 4)
if(!is.numeric(sig) || length(sig) != 4 || !all(sig > 0)) {
stop("sigma must be a positive scalar or vector of length four.")
}
list(mu, sig)
}
#lvcheck <- mvn.hyper.checkCompiling and checking the prior
Now we are ready to create the sde.model object:
data.names <- c("H", "L")
param.names <- c("alpha", "beta", "gamma")
lvmod2 <- sde.make.model(ModelFile = "lotvolModel.h",
PriorFile = "lotvolPrior.h", # prior specification
hyper.check = lvcheck, # prior input checking
data.names = data.names,
param.names = param.names)We can also test the C++ implementation of the prior against one written in R, using the msde function sde.prior().
# generate some test values
nreta <- 12
x0 <- c(H = 71, L = 79)
theta0 <- c(alpha = .5, beta = .0025, gamma = .3)
X <- jit.vec(x0, nreta)
Theta <- jit.vec(theta0, nreta)
Eta <- cbind(Theta, L = X[,"L"])
nrphi <- 5
Phi <- lapply(1:nrphi, function(ii) list(mu = rnorm(4), sigma = rexp(4)))
# prior check
# R version
lpi.R <- matrix(NA, nreta, nrphi)
for(ii in 1:nrphi) {
lpi.R[,ii] <- colSums(dlnorm(x = t(Eta),
meanlog = Phi[[ii]]$mu,
sdlog = Phi[[ii]]$sigma, log = TRUE))
}
# C++ version
lpi.cpp <- matrix(NA, nreta, nrphi)
for(ii in 1:nrphi) {
lpi.cpp[,ii] <- sde.prior(model = lvmod2, theta = Theta, x = X,
hyper = Phi[[ii]])
}
# compare
max.diff(lpi.R, lpi.cpp)## abs rel
## 1.136868e-13 1.762244e-16Installation
The msde package requires on-the-fly C++ compiling of user-specified models which is handled through the R package Rcpp (Eddelbuettel and François 2011).
Enable C++ compiling for R
- For Windows, install Rtools. Let the installer modify your system variable
Path. - For OS X, install the Xcode command line tools. To do this, open Terminal and run
xcode-select --install. You can simply press “Install” without obtaining the entire Xcode suite. - For Linux, install
build-essentialand a recent version of g++ or clang++.
To make sure the C++ compiler is set up correctly, install the Rcpp package and from within R run the following:
Rcpp::cppFunction("double AddTest(double x, double y) {return x + y;}")
AddTest(5.2, 3.4)If the code compiles and outputs 8.6 then the C++ compiler is interfaced with R correctly.
Optimize settings for the C++ compiler (optional)
It’s possible to speed up msde by a reasonable amount by passing a few flags to the C++ compiler. This can be done by creating a Makevars file (or Makevars.win on Windows). To do this, find your home folder by running the R command Sys.getenv("HOME"), and in that folder create a subfolder called .R containing the Makevars file (if it doesn’t exist already). Now add the following lines to th .R/Makevars file:
The first two options make the C++ code faster and the third uses the clang++ compiler instead of g++, which has better error messages (and is the default compiler on OS X).
Enable OpenMP support (optional)
On a multicore machine, msde can parallelize some of its computations with OpenMP directives. This can’t be done through R on Windows and is supported by default on recent versions of g++/clang++ on Linux. For OS X, the default version of clang++ does not support OpenMP but it is supported by that of the LLVM Project. This can be installed through Homebrew. After installing Homebrew using the instructions from the previous link, in Terminal run brew install llvm. Then have R use LLVM’s clang++ compiler by setting the following in .R/Makevars:
CXXFLAGS=-I/usr/local/opt/llvm/include -O3 -ffast-math
LDFLAGS=-L/usr/local/opt/llvm/lib
CXX=/usr/local/opt/llvm/bin/clang++Note that these compiler directives alone will not enable OpenMP support. This happens at compile time by linking against -fopenmp, which is done internally by msde.
References
Eddelbuettel, D. and François, R., 2011. Rcpp: Seamless R and C++ integration. Journal of Statistical Software, 40 (8), 1–18.
Golightly, A. and Wilkinson, D.J., 2010. Discussion of ‘Particle Markov chain Monte Carlo methods’ by Christophe Andrieu, Arnaud Doucet, Roman Holenstein. JRSS B, 59 (2), 341–357.
Maruyama, G., 1955. Continuous Markov processes and stochastic equations. Rendiconti del Circolo Matematico di Palermo, 4 (1), 48–90.
Pedersen, A.R., 1995. A new approach to maximum likelihood estimation for stochastic differential equations based on discrete observations. Scandinavian Journal of Statistics, 22 (1), 55–71.